
Abstract
Document-oriented databases are great. But they are not the silver bullet, you are probably searching for the whole time. Be aware of the advantages and disadvantages. If you use them at the right place (e.g. for another messaging application J), you get better results in a shorter time as in the classical way.
General
I want to share to you to some presentation, I created for colleagues of mine who are new to document oriented databases.
Document oriented database (or document DB) were introduced with Web 2.0 in the early 2000’s. With others so called NoSQL databases, document DBs focused on semi-structured data which appear in several web application. When you imagine a chat where someone starts a discussion with a post and another reader answers it. Someone else answers the answer and a fourth reader answers to the first entry. You get some kind of hierarchy with different entries in different length with quite different relations. Those things are difficult to model in a classic relational database.
So called NoSQL databases (Not only SQL) were developed to address exactly those scenarios. They started as simple key-value databases, which became more and more complex (and more specific). Document oriented databases are databases which are able to store a multiple of those key value pairs as one document.
Document oriented databases are e.g. Couchbase Server, Elasticsearch, or Cosmos DB. I created my samples in this document based on Mongo DB and use the wording of MongoDB. The naming might be slightly different in the other databases – but the concepts are definitely the same.
Comparison between SQL and Document Oriented Databases
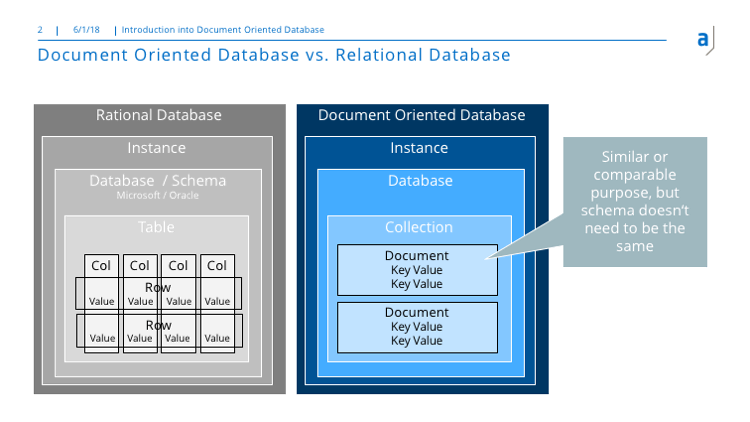
The picture shows the hierarchy of different parts of database.
In both worlds, we know an instance of a database, which means the installation of the database software on one or several computing nodes.
An instance has usually one or more databases (as would be called in the Microsoft world) or schemas (as we know it from Oracle). In the world of a document-oriented databases, we find databases as well – which is not quite surprising.
Tables as we know them in the SQL world, are presented by collections in the document-oriented world.
Tables are structured in columns and rows, whereas at one crossing of them the data values are stored. Document oriented databases don’t have such strong structures. They store documents. Those documents have their own structure defined by key value pairs. But the documents stored in one collection don’t need to have the same internal structure. That is the main difference and make the usage document databases so tempting, because I don’t need to take care about the internal structure so deeply.
Some Sample Documents
Let us assume that we want to program some donation application. A user can donate some money to a wild living animal. Our database should contain some information about wild living animals in general, certain specific specimen, and the donation done for them.
A document for a general animal could like the sample below.
{"_id":"5b070353729cb01f7a9847f6",
"family":"Elephantidae",
"species":"African elephant"}
As one can see, we have here some ID. The ID is generated by the database itself – as we know it out of SQL databases as well. The ID in MongoDB has even some meaning. It contains a timestamp, a machine ID, a process ID, and some kind of counter. In other databases the document ID might look differently – but the meaning is the same. Afterwards we have two key value pairs: family and species.
When a specimen of such an animal is born, a new document is created as shown below.
{"_id":"5b070472729cb01f7a9847f8",
"family":"Felidae",
"species":"Lion",
"name":"Peter",
"gender":"male",
"birthday":"2016-04-27T22:00:00.000Z"}
We see that we don’t have relation to the “general animal”, we simply copy the entries of the general and enhance such a document by the additional information: name, gender, birthday.
Those documents can contain embedded documents as well. Let us see how the document looks like with donations and detail information about the specimen.
{"_id":"5b0af6507baa0209ed0186b1",
"family":"Hominidae",
"species":"Bonobo",
"name":"Zumarani",
"gender":"male",
"birthday":"2018-01-16T00:00:00.000Z",
"godparents":[
{"donator":"John Doe",
"donation":{
"period":"yearly",
"amount":{"$numberDecimal":"100"}}},
{"donator":"Jenny Doe",
"donation":{
"period":"yearly",
"amount":{"$numberDecimal":"50"}}}],
"details":{
"weight":{"$numberDecimal":"50”},
"eyecolor":"black",
”height":{"$numberDecimal":"95"}}}
We have here two embedded documents “godparents” and “details”. The godparents document is even not only one document it is an array of embedded documents – one donation from John and one donation from Jenny (of course Bonobos are quite cute). Both embedded documents contain even another embedded document with donation again. Those structures could be modelled in SQL easily as well with table and according foreign keys. But here I have everything together in one document.
Querying Documents
Storing documents in a database is quite fine. As long as I can’t query them, such a database wouldn’t make any sense. Even the queries look a little bit like a document. If I want to find all documents where the family is “Elephantidae”, I only have to give the field name “family” and the value I want to search for. Moreover, the query language provides some operators as well. E.g. with the “in” operator you can get all documents (animals and specimen including donations) where the family is either Hominidae or Elephatidae.
{family: {$in: [“Hominidae“, “Elephantidae“]}}
In the same manner, comparison operators like “larger then” or logical operators like “not” are provided. For further information have a look into the various online courses.
Modelling of Document Oriented Databases
As we saw in the paragraph before, we can use embedded documents. But the document-oriented databases provide links to other documents as well. The referenced document is given by its ID, which works as foreign key in a classical SQL database. In our sample above, we could have a separated collection of donators. Then we would have not name with “John”. We probably would have an object ID (which means a document ID) referencing to John as a registered user of the donation web site.
{"_id":"5b0af6507baa0209ed0186b1",
"family":"Hominidae",
"species":"Bonobo",
"name":"Zumarani",
…
"godparents":[
{"donator":"5b0c3d7c9720510c20ab513a”,
"donation":{ …
A query needs to nest those keys – because document-oriented databases don’t provide joins, as we know them of SQL databases. But when we always need to have the current information for the donator and we can’t update all referenced documents with the donators current information recursively, we need to separate the documents (probably in such a case where you have a lot of those situation you need to go for the uncool SQL solution).
In general, we need to consider the following rules, when it comes to model document-oriented databases.
- Combine objects into one document if you will use them together. Otherwise separate them (but make sure there isn’t the need of joins)
- Duplicate the data (but limited) because disk space is cheap as compare to compute time
- Do joins while write, not on read
- Optimize your schema for most frequent use cases
Even though the document-oriented databases don’t provide joins, we query them. Therefore, we need indexes as in each other database. Those indexes have to be planned carefully as we know it from SQL databases. A re-indexing can become quite time-expensive, depending on the number of documents in the database. But to start only with an index on the document ID would not be so wrong.
Failover
As you might know, one of the most critical points in using databases is the failover. Many failover concepts were provided in the past. Nowadays, any outage of a web application even in the B2B area is not accepted anymore. Therefore, we need high-reliable and highly stable dataset application.
Mongo DB provides replica sets as shown in the next picture.
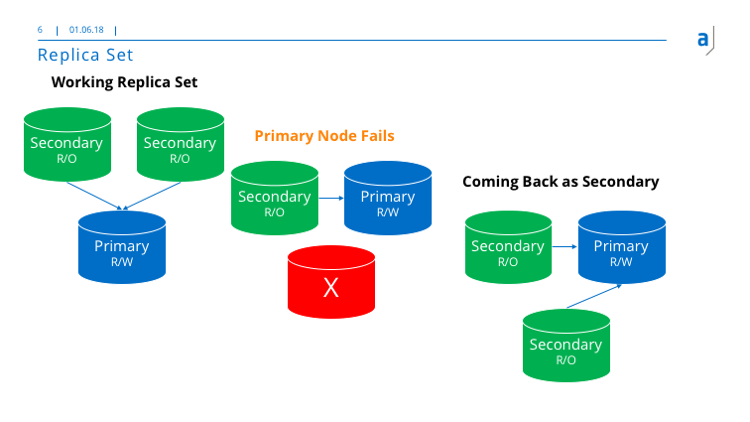
The replica set is created out of three nodes at minimum. There is one primary read-write node and several secondary read-only nodes. But the replica set contains at least two secondary nodes. All nodes are in synch controlled by the database. If the primary node fails, one of the secondary nodes becomes the primary node. If the node comes up again, it becomes a secondary node and the primary node remains. In such a way, the replica set is highly reliable and stable.
Summary
Document-oriented databases are great. But they are not the silver bullet, you are probably searching for the whole time. Be aware of the advantages and disadvantages. If you use them at the right place (e.g. for another messaging application J), you get better results in a shorter time as in the classical way.
Literature
Online Tutorial: https://www.tutorialspoint.com/mongodb/mongodb_overview.htm
MongoDB Resource Center: https://www.mongodb.com/resource-center
Banker, K.; Bakkum, P.: MongoDB in Action, Manning Pubn, 2014, ISBN-13: 978-1617291609
