
Abstract
Dokumenten-Orientierte Datenbanken sind großartig. Aber sie sind kein Allheilmittel, das Du die ganze Zeit suchst. Sei Dir der Vorteile und der Nachteile bewusst. Wenn Du sie an der richtigen Stelle einsetzt (z.B. für eine weitere Messaging-Applikation J), bekommst Du bessere Ergebnisse in kürzerer Zeit als auf dem klassischen Weg.
Einführung
Ich möchte eine Präsentation teilen, die ich für meine Kollegen erstellt habe, die noch keine Berührung mit Dokumenten-orientierten Datenbanken hatten.
Dokumenten-orientierte Datenbanken wurden mit dem Web 2.0 in den frühen 2000er eingeführt. Wie anderen sogenannten NoSQL-Datenbanken fokussieren Dokumenten-orientierte Datenbanken auf semi-strukturierte Daten, wie sie in vielen Web-Anwendungen auftauchen. Wenn Du Dir einen Chat vorstellst, indem jemand eine Diskussion mit einem Post startet. Jemand anderes antwortet auf diesen Post, wieder jemand anderes antwortet auf diese Antwort und ein vierter Leser antwortet wiederum auf den ersten Eintrag. Man bekommt eine Art Hierarchie mit unterschiedlichen Längen und vielen unterschiedlichen Relationen. Solche Dinge lassen sich nur schwierig in einer relationalen Datenbank abbilden.
So genannte NoSQL Datenbanken (Not only SQL) wurden entwickelt, um genau diese Szenarios lösen. Es begann mit einfachen Key-Value-Datenbanken (Schlüssel – Wert), die mehr und mehr komplex (und spezifischer) wurden. Dokumenten-orientierte Datenbanken sind Datenbanken, die in der Lage sind, mehrere solcher Key-Value-Paare in einem Dokument zu speichern.
Vergleich zwischen SQL und Dokument-orientierte Datenbanken
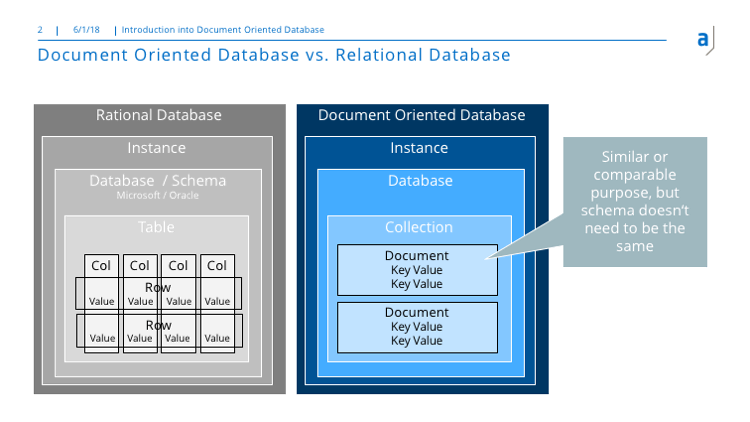
Eine Instanz enthält eine oder mehrere Datenbanken (wie es in der Microsoft-Welt heißt) oder auch Schemas (wie es in der Oracle-Welt genannt wird). In der Welt der Dokumenten-orientierten Datenbanken finden auch Datenbanken, was nicht wirklich überraschend ist.
Tabellen, wie wir sie in der SQL-Welt kennen, werden durch Collections in der Dokumenten-orientierten Welt repräsentiert.Tabellen sind in Spalten und Zeilen organisiert, wobei die Daten an einer Kreuzung gespeichert werden. Dokumenten-orientierte Datenbanken haben keine solche starke Struktur. In ihnen werden Dokumente gespeichert. Die Dokumente haben ihre eigene Struktur, die durch die Key-Value-Paare definiert wird. Aber die Dokumente, die in einer Collection gespeichert werden, müssen nicht unbedingt die gleiche interne Struktur haben. Das ist der Hauptunterschied und macht Dokumenten-orientierte Datenbanken so verführerisch, weil man nicht ganz so penibel auf die interne Struktur achten muss.
Einige Beispieldokumente
Lasst uns annehmen, dass wir eine Spenden-Applikation entwickeln wollen. Ein Benutzer kann für ein wildlebendes Tier spenden. Unsere Datenbank sollte Informationen über wildlebende Tiere im Allgemeinen, bestimme spezifische Exemplare und die Spende, die für sie getätigt wurde.
Ein Dokument für ein Tier im Allgemeinen könnte wie folgt aussehen:
{"_id":"5b070353729cb01f7a9847f6",
"family":"Elephantidae",
"species":"African elephant"}
Wie man sehen kann, haben wir hier eine ID. Diese ID wird durch die Datenbank selbst generiert – wie es auch von SQL-Datenbanken kennen. Die Dokumenten-ID hat in der Mongo DB eine gewisse Semantik. Sie enthält einen Zeitstempel, eine Maschinenidentifikation, eine Prozessidentifikation und einen fortlaufenden Zähler. In anderen Datenbanken kann die Dokument-ID anders ausschauen, aber es bleibt das gleiche. Danach kommen zwei Key-Value-Paare: Family und Species.
Wenn ein Exemplar eines solchen Tieres geboren wird, wird ein neues Dokument, wie folgt, erzeugt.
{"_id":"5b070472729cb01f7a9847f8",
"family":"Felidae",
"species":"Lion",
"name":"Peter",
"gender":"male",
"birthday":"2016-04-27T22:00:00.000Z"}
Wir sehen, dass wir keine Relation von „Allgemeinen Tier“ haben. Die entsprechenden Einträge werden einfach in ein neues Dokument kopiert und durch die zusätzlichen Informationen: Name, Geschlecht und Geburtstag erweitert.
Solche Dokumente können auch eingebettete Dokumente enthalten. Lasst uns sehen, wie das Dokument aussieht, das die Spenden für ein bestimmtes Tier enthält.
{“_id”:”5b0af6507baa0209ed0186b1“,
“family”:”Hominidae“,
“species”:”Bonobo“,
“name”:”Zumarani“,
“gender”:”male“,
“birthday”:”2018-01-16T00:00:00.000Z“,
“godparents”:[
{“donator”:”John Doe“,
“donation”:{
“period”:”yearly“,
“amount”:{“$numberDecimal”:”100“}}},
{“donator”:”Jenny Doe“,
“donation”:{
“period”:”yearly”,
“amount”:{“$numberDecimal”:”50″}}}],
“details”:{
“weight”:{“$numberDecimal”:”50”},
“eyecolor”:”black“,
”height”:{“$numberDecimal”:”95″}}}
Wir haben hier zwei eingebettete Dokumente „godparents“ und „details“. Das „godparents“ Dokument ist nicht nur ein eingebettetes Dokument, es ist sogar ein Array von Dokumenten – eine Spende kommt von John und eine weitere von Jenny (natürlich Bonobos sind ja auch niedlich). Beide eingebettete Dokumente enthalten wiederum das eingebettete Dokument „donation“. Solche Strukturen könnten in SQL auch einfach mit Tabellen und Fremdschlüssel-Beziehungen modelliert werden. Aber hier habe wir alles in einem Dokument.
Abfrage von Dokumenten
Speichern von Dokumenten in einer Datenbank ist schön und gut. Solange Du sie nicht abfragen kannst, macht die Datenbank wenig Sinn. Sogar die Abfragen sehen ein bisschen wie Dokumente aus. Wenn ich alle Dokumente der Familie („family“) Elefanten („Elephantidae“) finden will, muss ich nur den Feldnamen „family“ und den Wert, nach dem ich suche, angeben. Mehr noch die Abfragesprache stellt auch Operatoren zur Verfügung. So kann man z.B. mit dem „in“ Operator nach allen Dokumenten suchen (allgemeine Tiere, Exemplare und Spenden), die den Familien Elefanten oder Menschenaffen zugeordnet sind.
{family: {$in: ["Hominidae", "Elephantidae"]}}
In der gleichen Art und Weise gibt es Vergleichsoperatoren wie „größer als“ oder logische Operatoren wie „nicht“ sind ebenfalls verfügbar.
Entwurf einer Dokumenten-orientierten Datenbank
Wie wir im Abschnitt bevor sahen, können wir eingebettete Dokumente verwenden. Aber Dokumenten-orientierte Datenbanken stellen auch Links zu anderen Dokumenten zur Verfügung. Die referenzierten Dokumente werden als Dokumenten-ID angegeben, die als Fremdschlüssel wie in einer SQL-Datenbank fungiert. In unserem obigen Beispiel könnten wir eine separierte Collection der Spender haben. Dann hätten wir als Spender nicht den Namen mit „John“, sondern eine ID. Wir hätten die Dokument-ID, die auf das Dokument mit John als registrierter Benutzer der Spenden-Webseite verweist.
{“_id”:”5b0af6507baa0209ed0186b1“,
“family”:”Hominidae“,
“species”:”Bonobo“,
“name”:”Zumarani“,
…
“godparents”:[
{“donator”:”5b0c3d7c9720510c20ab513a”,
“donation”:{ …
Eine Abfrage muss diese Schlüssel zusammenfassen – weil Dokumenten-orientierte Datenbanken keine Joins, wie SQL-Datenbanken zur Verfügung stellen. Aber wenn wir immer die aktuellste Information über einen Spender benötigen und nicht immer alle Dokumente, die die entsprechenden Informationen enthalten, rekursiv aktualisieren können, müssen wir die Dokumente separieren (wahrscheinlich ist es besser in einer Situation, in der viele dieser Fälle auftreten, eine uncoole SQL-Datenbank zu verwenden).
Im Allgemeinen müssen wir die folgenden Regeln bedenken, wenn wir eine Dokumentierte-orientierte Datenbank verwenden.
- Kombiniere Objekte, die zusammengehören, wenn Du sie zusammen verwenden willst. Andererseits separiere sie (sei aber sicher, dass Du keine Joins benötigst)
- Dupliziere die Daten (aber begrenzt), da es billiger ist zu speichern als zu berechnen
- Mache Joins beim Schreiben, nicht beim Lesen
- Optimiere Dein Schema für die am meisten benutzten Fälle
Obwohl Dokumenten-orientierte Datenbanken keine Joins zur Verfügung stellen, können wir sie abfragen. Daher benötigen wir Indizes, wie in jeder anderen Datenbank. Solche Indizes müssen sorgfältig geplant werden, wie wir es auch von SQL-Datenbanken kennen. Ein Re-Indizieren kann sehr zeitaufwändig – abhängig von der Anzahl der Dokumente in der Datenbank – sein. Aber mit einer indizierten Dokumenten-ID zu starten, kann auch nicht so fürchterlich falsch sein.
Ausfallsicherung
Wie Du wahrscheinlich weißt, ist die Ausfallsicherung einer der wichtigsten Punkte bei dem Aufbau und dem Nutzen von Datenbanken. Viele verschiedene Ausfallsicherungs-Konzepte wurden in der Vergangenheit entwickelt. Heutzutage ist der Ausfall einer Webapplikation – auch einer Business-zu-Business-Applikation – nicht mehr akzeptiert. Daher benötigen wir eine hoch stabile und verlässliche Datenbank.
Mongo DB stellt Replica Sets, wie sie im nächsten Bild gezeigt werden, zur Verfügung.
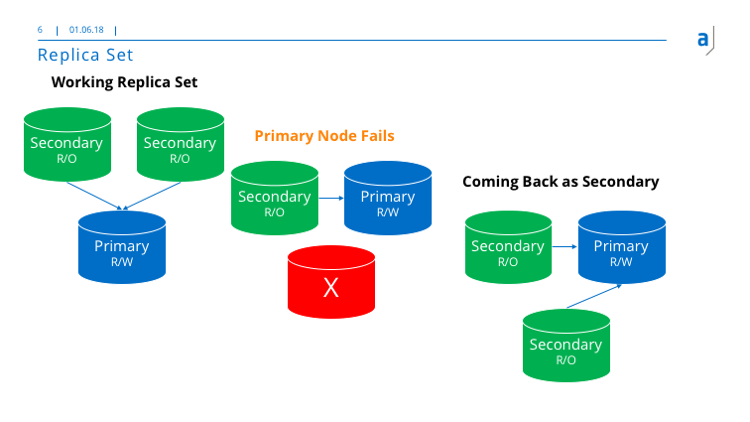
Ein Replica Set besteht aus minimal drei Nodes. Es sind ein primärer Lese-Schreib-Knoten und mehrere sekundäre Nur-Lese-Knoten. Das Replica Set enthält minimal zwei sekundäre Nur-Lese-Knoten. Alle Knoten werden durch die Datenbank gesteuert. Wenn der primäre Knoten ausfällt, übernimmt einer der sekundären Knoten diese Aufgabe. Wenn der Knoten wieder verfügbar ist, wird er zum sekundären Knoten und der primäre Knoten bleibt wie er ist. So ist das Replica Set hochverfügbar und stabil.
Zusammenfassung
Dokumenten-Orientierte Datenbanken sind großartig. Aber sie sind kein Allheilmittel, das Du die ganze Zeit suchst. Sei Dir der Vorteile und der Nachteile bewusst. Wenn Du sie an der richtigen Stelle einsetzt (z.B. für eine weitere Messaging-Applikation J), bekommst Du bessere Ergebnisse in kürzerer Zeit als auf dem klassischen Weg.
Literatur
Online Tutorial: https://www.tutorialspoint.com/mongodb/mongodb_overview.htm
MongoDB Resource Center: https://www.mongodb.com/resource-center
Banker, K.; Bakkum, P.: MongoDB in Action, Manning Pubn, 2014, ISBN-13: 978-1617291609
