
I’m often asked to explain to someone technical things, where the knowledge base is quite limited. In a book about enterprise architecture, I read “how to explain to my girlfriend”. That is not only politically incorrect, I can’t apply this to myself: first I’m a female, second my husband is a software architect himself. Therefore, I want to call it “how to explain it to my manager”, even though it’s not politically correct as well. I for myself even know a lot of mangers with a quite good technical background. This time I want to explain containerization (upps what’s that ;-)) and online deployment. When you saw the header and think: where is my containerization – you can step forward to the second part of this post. In the first part I want to explain deployment and how to do it online.
What is Deployment at All?
Probably the one or the other of you can remember those times where large monoliths were deployed in even larger downtimes of 10 or more hours. The entire process was really expensive and error prone. These days with all those online services like Uber or AirBnB or streaming services like Netflix, such downtimes are totally unthinkable. Even for applications in Business to Business Area, where we only rely on so called business hours, we expect simply no downtimes. Or as managers would express it: “Amazon can do it. Why not we?”.
And to be honest he or she is right. Why not we? Online deployment is not such a mystery as it first seems. But one has to have some technical dependencies in his or her mind to make it happen successfully.
Applications are deployed on servers. What does that mean? We have a server, whereas a server means the hardware inclusive the operational system. And we have our software, which includes a code which can run on a machine or as it is in Java on a virtual machine. Oh my god – I want to make it easier and now I make it even more difficult. But as far as you must know it, you have an operational system with probably a virtual machine (depending on the selected program language).

Figure 1 Schematic presentation of a server
When I want to deploy a new application or better a new version of an existing application, I need to bring the new application to the server and probably to adapt settings in the operation system and in the virtual system. Unfortunately, those changes to the entire system take only effect when the server is completely rebooted. That obviously needs some downtimes. A single server is not enough in our modern world. We need several so-called nodes in a cluster (OK – the words a explained in a box in the end J, I apologize for so many unusual words). The nodes act as failover. When one node is not working anymore, another node is able to take over. The taking over is done by the cluster software. Moreover, the load coming from the outside can be balanced out over the multiple nodes. Such a balancing out is done by a loadbalancer (as the you can assume by the name :-)).
Even more the server is not alone, usually to an application belongs a database, which needs to be updated as well. Therefore, a typical downtime cycle in our good old world would be
- Close loadbalancer
- Make a roll-back point of the database
- Stop application server
- Update database
- Restart database
- Update application
- Adapt server settings
- Restart application server
- Test application
- Open loadbalancer
As you can see, it’s quite clear that between point 1 and 10 the entire team has a lot to do.
How can Online-Deployment make the world better?
In an online deployment, one can use the functionality of a loadbalancer to put out single nodes or even full clusters from outside access (which means usually user interaction, but it can mean backend messages from customers as well).
For a single node the following procedure can be done:
- Make a roll-back point of the database
- Update database
- Put node out of loadbalancing
- Update application
- Adapt server settings
- Restart application server
- Test application
- Put node back in loadbalancing
- Put out next node from loadbalancing
- Update application
- …
- Put last node back in loadbalancing
Such a process is usually called Canary deployment because like Canary birds some users sing the new song and others the classical one until all of them sing the new one.
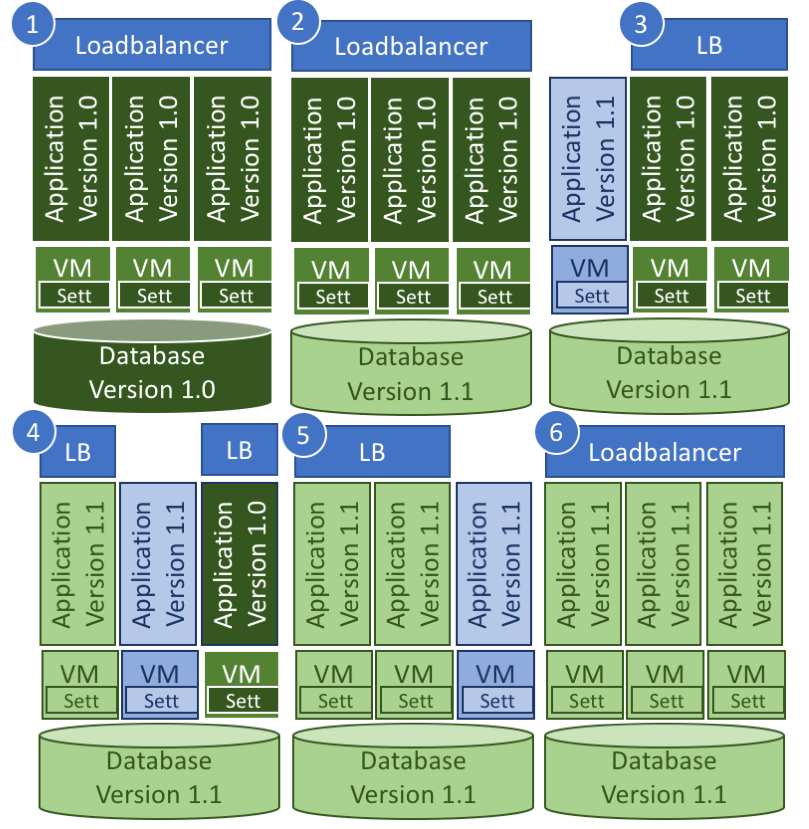
Figure 2 Sample process of a canary online deployment
As you can see the blue node is taken out of the loadbalancing and updated afterwards it is put back into loadbalancing. The green nodes are inside of loadbalancing – the dark green indicates the former version and the light green the new version. Both versions are accessible by users in parallel. Both versions work on one database. That even means that the database needs to be updated first and the database version has to ensure that older application versions can work with a new database version. Usually this is possible. Of course, one could have two databases for updating, but usually that is too expensive in point of view of storage as well as license costs.
This method has some kind of disadvantages. First of all, one node needs to be out of the loadbalancing and is not available anymore for the users. That disadvantage can overcome by an additional node, which is always in the blue. The other disadvantage is that tests can only be run on one node. Difficulties which are created by synchronization issues between the nodes in one cluster can’t be detected in such a way. Additionally, a rollback of the new software in case it contains serious failure is difficult to be done.
For those applications a green-blue approach can be used.
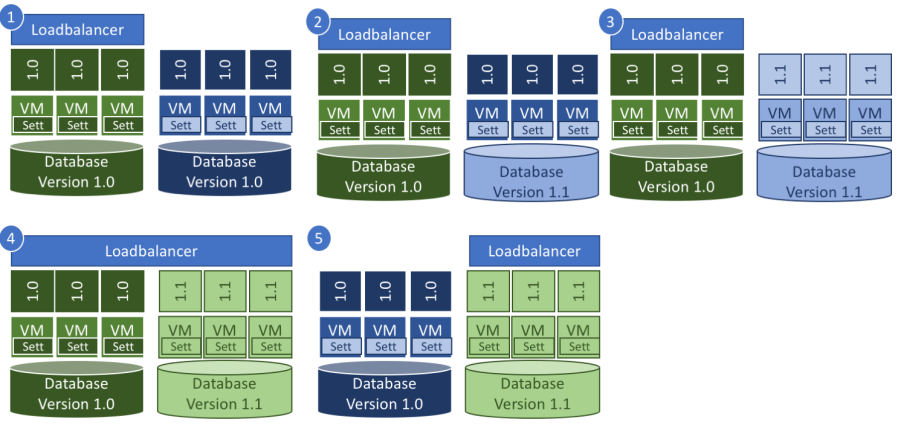
Figure 3 Blue-green approach at online deployment
As you can see, such an approach needs a doubled infrastructure more or less. You have one green line with three nodes and a blue line with three nodes as well. The green line is accessible by users, whereas the blue line isn’t. The update mechanism updates the complete blue line. Then the green line and the line with the new version become accessible to the users. At the loadbalancer, a rule is defined that users who are login to the system during that period are routed only to the new system. In such a way step by step all users are using the new system. When no user uses the old version anymore, the loadbalancer only provides the new version and the old version becomes the blue line.
The blue-green method is shown here with two databases. But one can do it with a one database as well. The arguments as mentioned at the Canary version are the same as here.
The blue-green version creates higher costs as the Canary version, but it is more reliable. The users get always the same number of nodes in one of the lines. In the intermediate state, where both versions are active, the users can access even more nodes than usual. Most of all, it is really easy to roll back – because you only have to switch the loadbalancer from the current green line to the current blue line. Such a risk mitigation usually pays back the more costs of the inactive line.
Container
The entire game becomes even more easier, when we don’t speak about virtual machines and applications, when we speak about containers. When we imagine that we have not only an application to deploy, we imagine we have an entire infrastructure as code, the entire game becomes even more interesting. That is what we call “Container” and I will talk about in the next chapter. In a technical surrounding, one doesn’t want to do manual steps e.g. to enter manually a URL. What one want is automatic procedures. So, our processes as described before should run completely automatic. That can’t be done in a classical environment even though you might already use virtual machine. To get a complete automation, you need to use containers.
A container is a package of software modules which not only contains the application, it contains the operations system as well. So, you don’t need to adapt the settings in operation system as shown before. You only need to provide the entire package. Those packages can be moved from one environment to another without any changes to do to them. From the outside such a container looks like his neighbor, even though their content might be completely different. Therefore, they are called containers – like the name givers on sea. A typical software which can be used for it, is Docker.

Figure 4 Container principles
Container Management
But as we saw above we need applications for different purposes e.g. we need the application nodes, we need certain scripts on the loadbalancer and so on. To automate the deployment as well as an automated scaling, we need containerization management software like Kubernetes. Such a software manages mostly automatic when new versions of software are available. If a new software is pushed to a version control system, the management software is able to create according containers and to deploy them to the cluster completely automatically. The management software can be scripted (programmed) in which way the deployment should be done – e.g. Canary style or blue-green approach.

Figure 5 Kubernetes as sample for a containerization management software
Moreover, inside of the management software, certain criteria can be defined, when automatically new nodes should be added, or nodes should be removed. In such a way, the entire cluster can react on increasing or decreasing request numbers e.g. by an increasing number of users. In such a way the entire environment can be automatically scaled. That will be done via a management interface. Users can access such a cluster via a proxy, so that it seems for him like a normal server.
That is not only interesting because of automation. It is interesting when you want to deploy your application in the cloud. Usually the servers in the cloud are charged by period e.g. minutes. When you are able to react automatically on load, you can save a lot of money.
Conclusion
Online Deployment is an absolute Must nowadays. You don’t need to use containers and container management software to have a working online deployment. But it helps you to have reliable to fast processes to bring new software to the customers.
Terms
| Term | Description |
| Cluster | A cluster is a system of several servers which usually have the same tasks. Additional to this, a cluster contains some kind of management software – probably deployed on its own node. |
| Container | Container software allows to put applications and a belonging operation system together. To do so allows to move containers around without manual processes necessary. (Wikipedia: Docker is a computer program that performs operating-system-level virtualization also known as containerization. https://en.wikipedia.org/wiki/Docker_(software)) |
| Container Management | Container management software allows to put containers with different purposes e.g. application container and loadbalancer together in a cluster without manual processes. (Wikipedia: Kubernetes (commonly stylized as K8s) is an open-source container-orchestration system for automating deployment, scaling and management of containerized applications. |
| Database | Database means here the definition of data structure and the data themselves of a particular application |
| Database server | Database server means here the database software and the server where the database software is running. |
| JVM | Java Virtual Machine – see Virtual machine |
| Loadbalancer | A loadbalancer is usually a hardware-software-combination which allows to balance out requests to an application over several nodes. |
| Node | A node is a single server in a cluster. |
| Proxy | Proxy is an infrastructure concept where severs are hidden behind some kind of software component so that it seems to the user like one server, so it is an intermediary between the user and the servers behind |
| Server | Server means here the combination of hard- and software. Sometimes only software is meant, in case specialized software can take over the part of the hardware (see virtualized systems as well) |
| Virtual machine | Virtual machine means a software which abstracts the machine code from the application. In such a way, a program can run on quite different machines without being compiled to the particular machine code of a particular machine. Virtual machines are used in the Java world. Therefore, they are called Java Virtual Machine or JVM. The programming languages Scala and Kotlin are using besides Java the JVM as well. |
| Downtime | Time in which a web application cannot be reached by users – opposite of uptime |
| Uptime | Time in which a web application is reachable by users – opposite of downtime |
| Rollback | Rollback means that an already installed new version of a software is rolled back to an earlier version |
